Generative AI
Some notes from the Coursera Course
Created:
Some notes from the Coursera Course
Generative AI Project Lifecycle
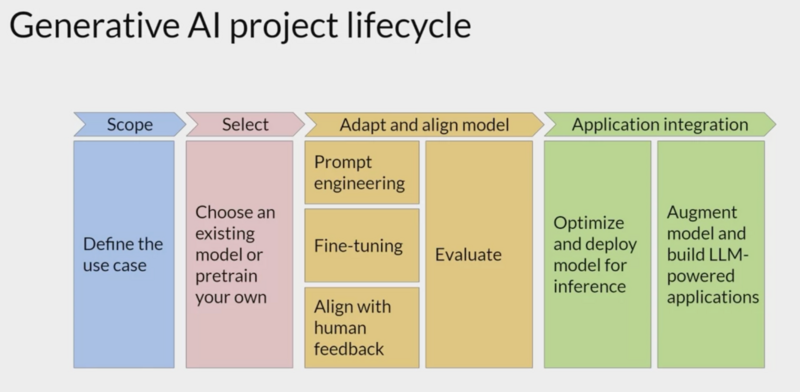
Uses AWS Sagemaker (Sagemaker Studio is Jupyter based IDE) for launching notebooks. Time limited to 2 hours.
pip packages: - torch - torch-data - transformers (these two are from huggingface) - datasets (helps load common datasets)


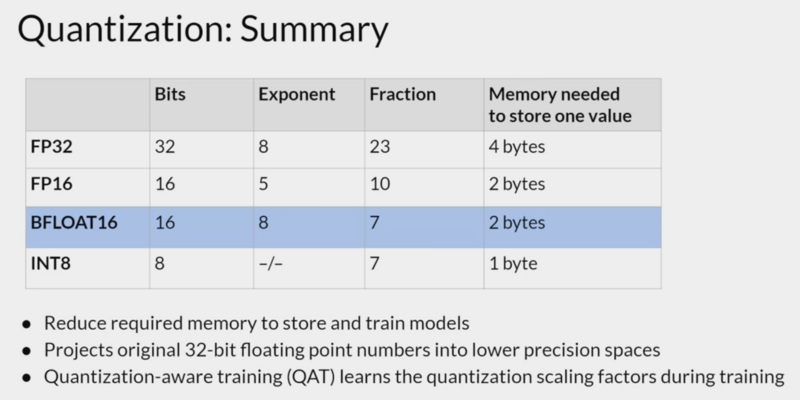
Quantization
Reduce the memory needed to store and train models.
BFLOAT16 = (google) brain floating point format, 16
bits. “BF16”. hybrid between half precision FP16 and full precision
FP32. Truncated FP32. Truncates the fraction to seven bits while uses
the full 8bits to represent the exponent. This also speeds up
calculation. The downside is that BF16 is not good for integer
calculations.
INT8, memory requirement 4 bytes to 1 byte.


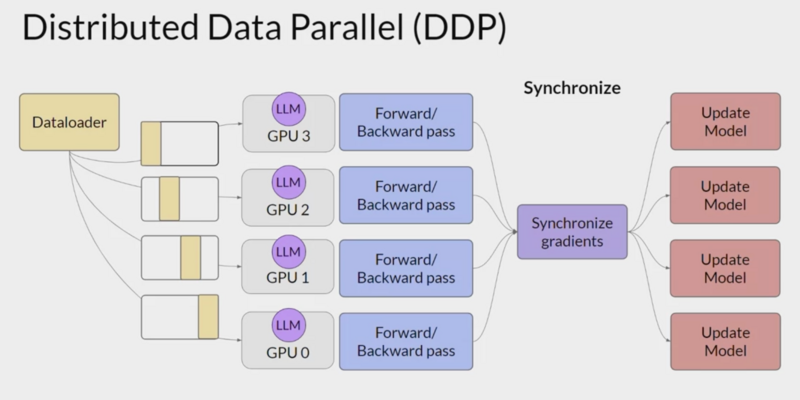
Efficient multi-GPU compute strategies
Distributed Data Parallel (DDP), pytorch.
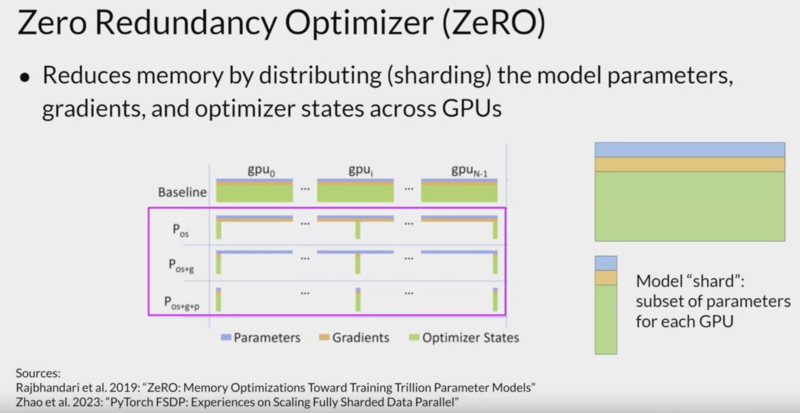
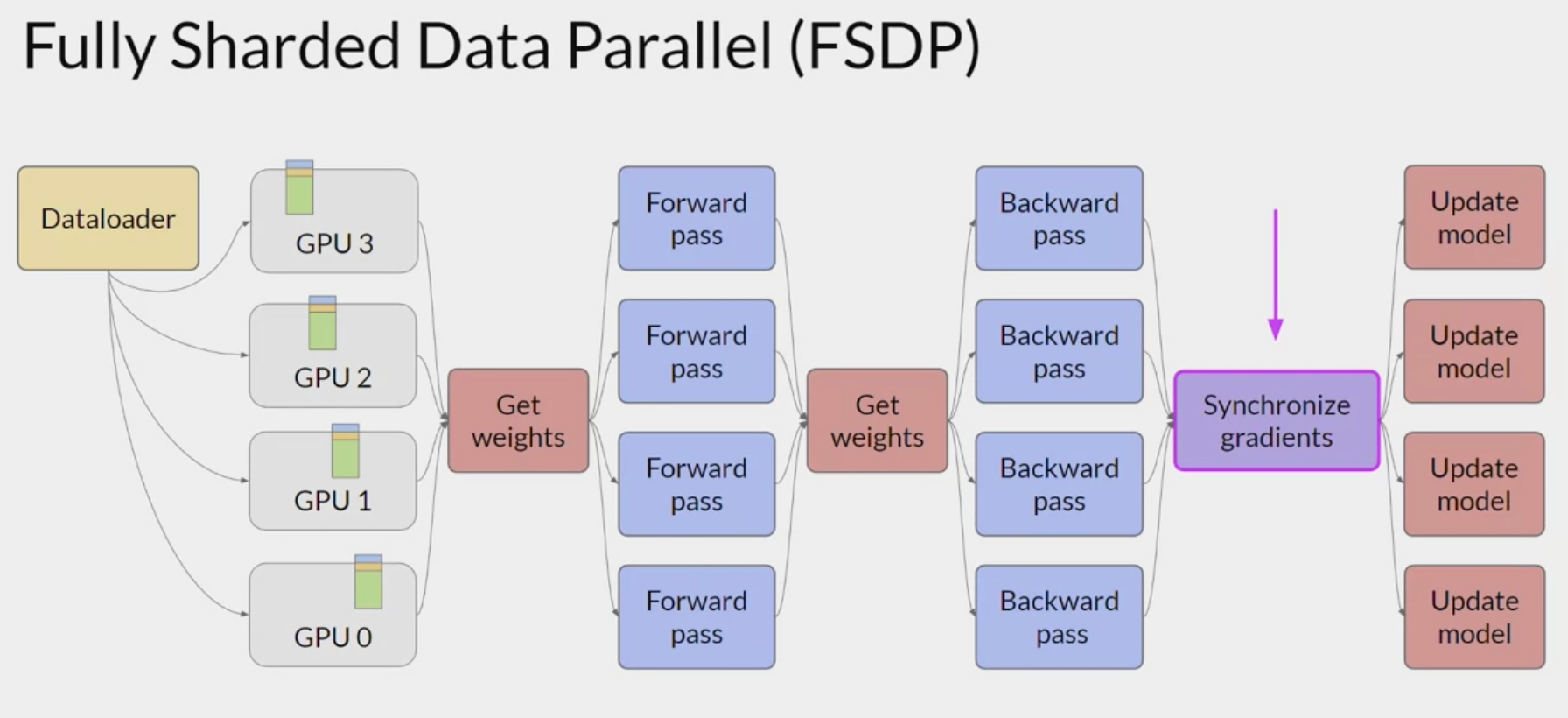
Full Sharded data parallel
uses Zero Redundancy Optimizer; Rajbhandari, Samyam, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. “ZeRO: Memory optimizations toward training trillion parameter models,” 2020. https://arxiv.org/abs/1910.02054.

from microsoft.

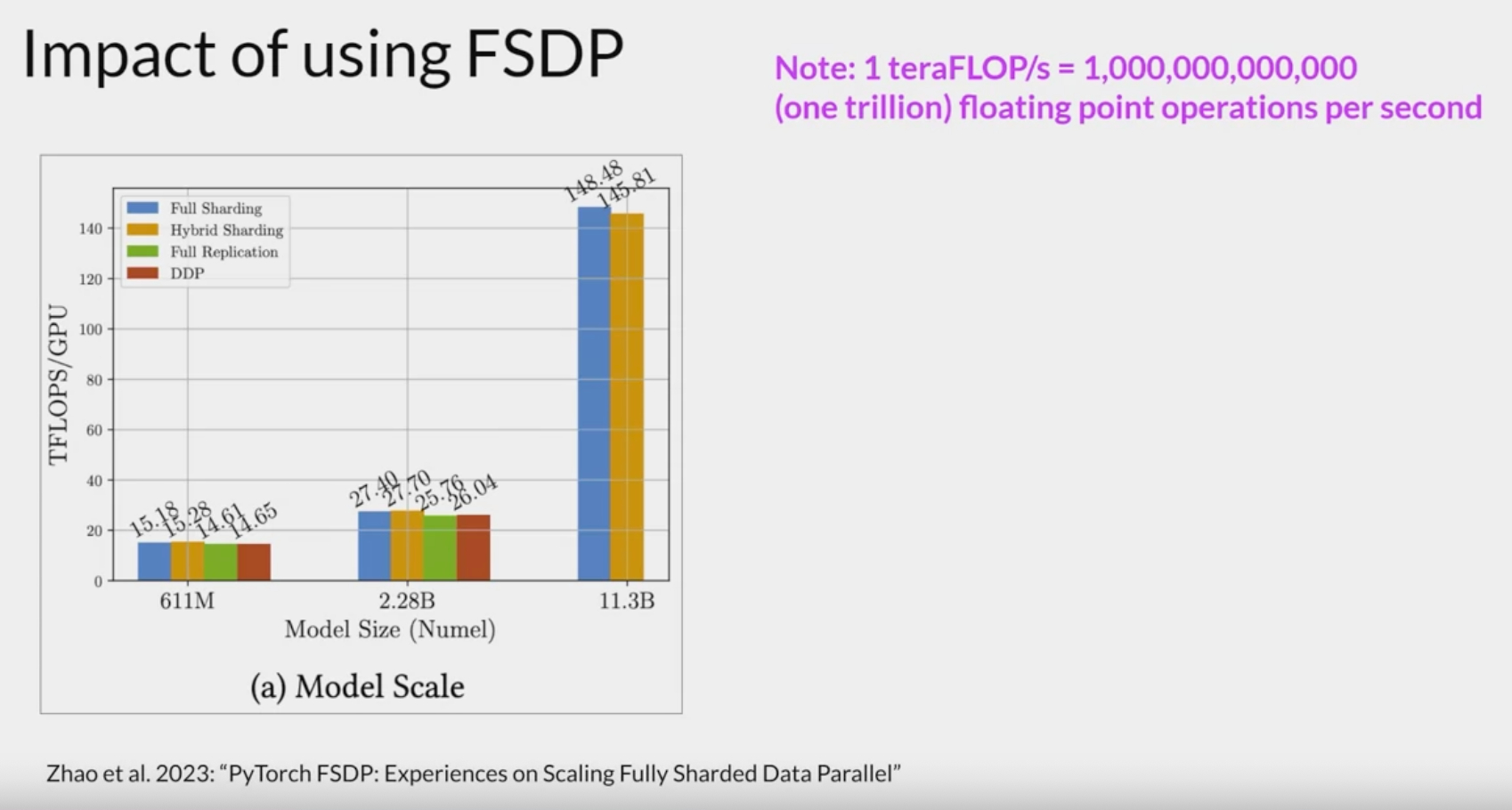
you can see the DDP model runs out of memory for the larger(11.3B) model, but the SFDP model succeeds. Zhao, Yanli, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, et al. “PyTorch FSDP: Experiences on scaling fully sharded data parallel,” 2023. https://arxiv.org/abs/2304.11277.
Scaling laws and compute-optimal models
research that has explored the relationship between model size, training, configuration and performance in an effort to determine just how big models need to be.
Kaplan, Jared, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. “Scaling laws for neural language models,” 2020. https://arxiv.org/abs/2001.08361.

Compute budgets
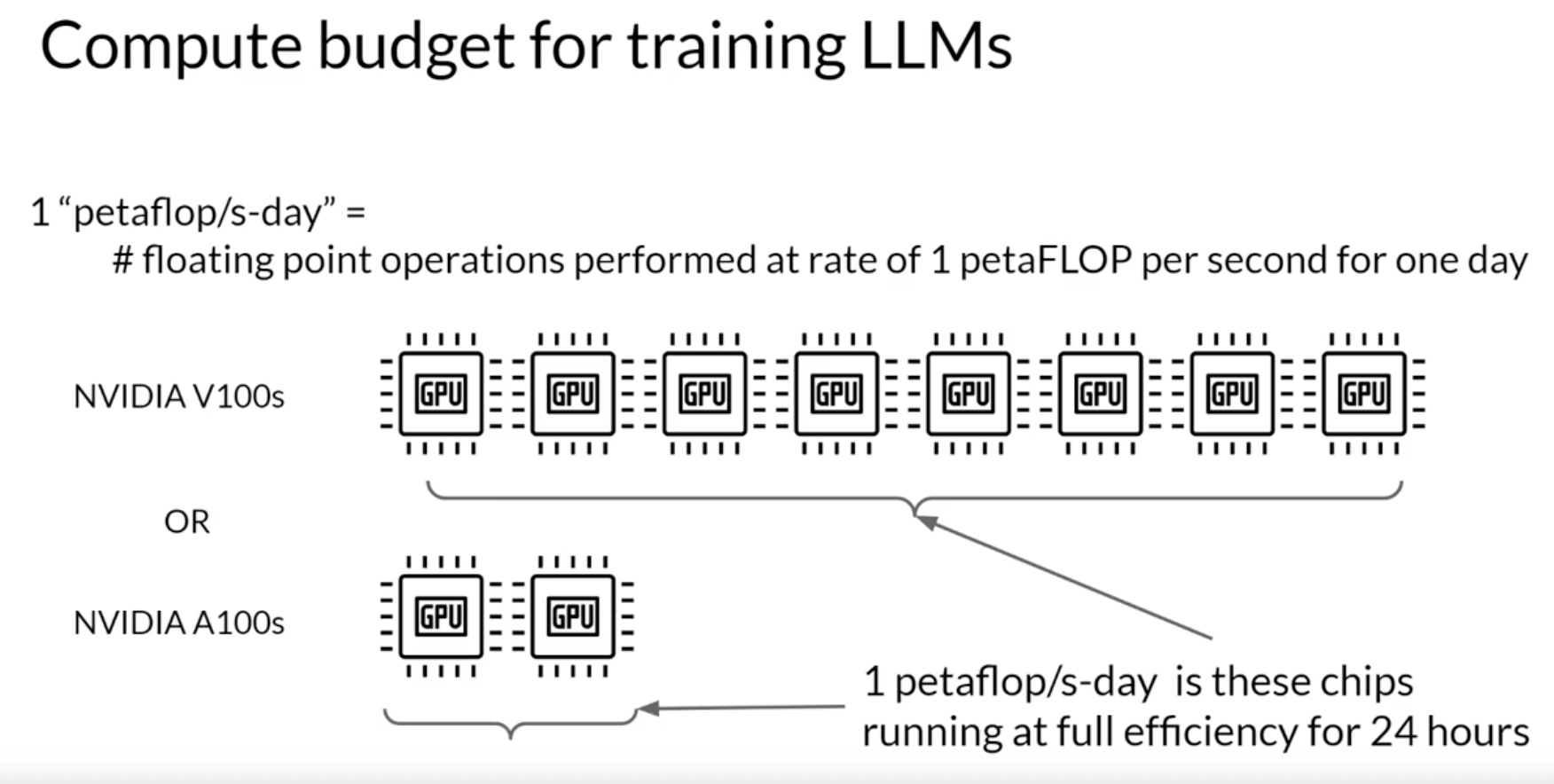
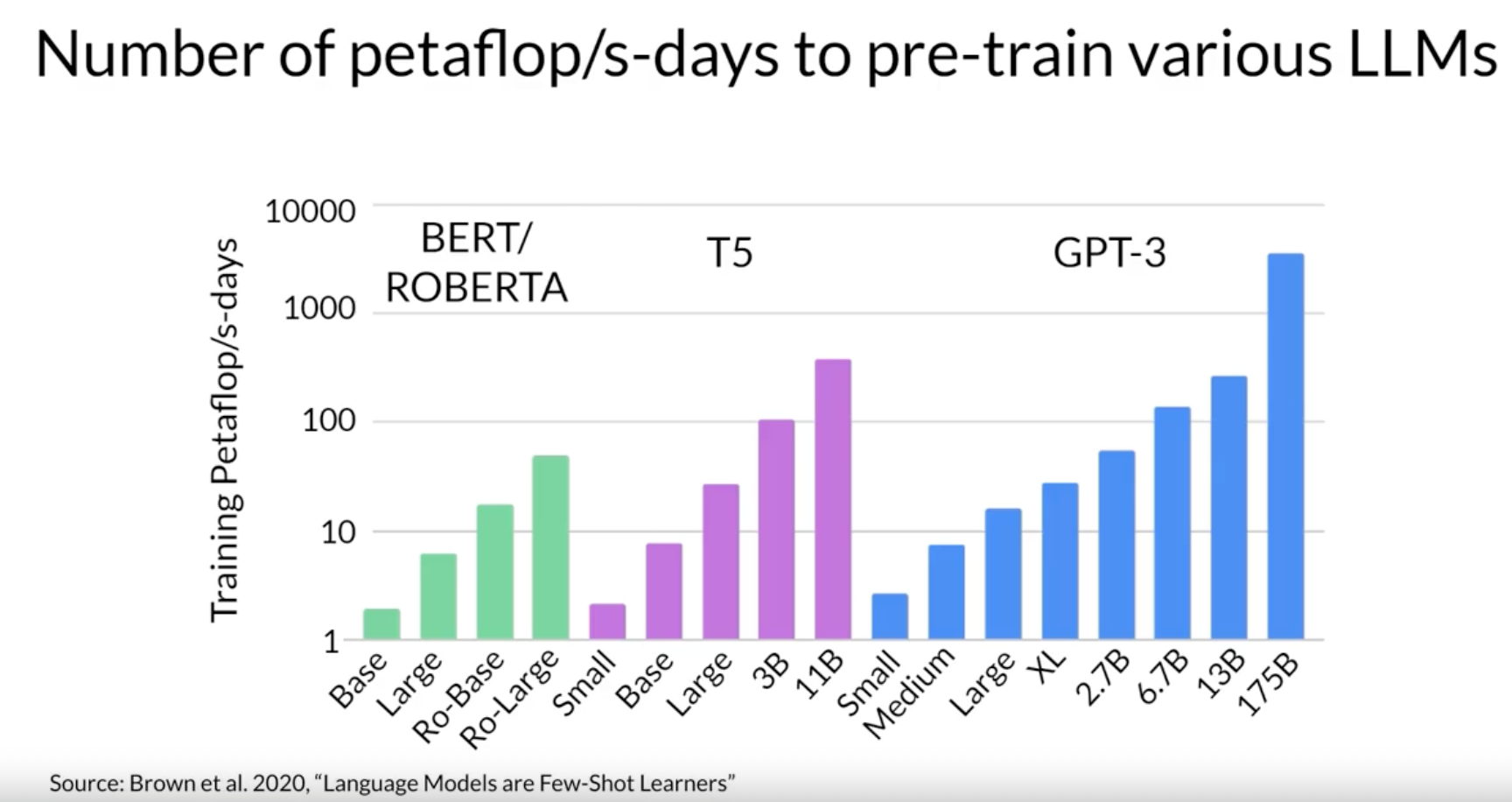
Number of petaflogs/s-days to pre-train various LLMs. Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. “Language models are few-shot learners,” 2020. https://arxiv.org/abs/2005.14165.
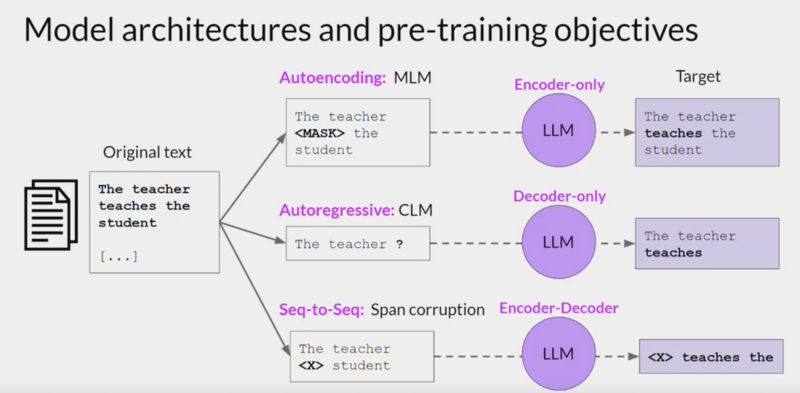
- BERT/ROBERTA are encoder models
- T5 is encoder/decoder models
- GPT-3 is a decoder model
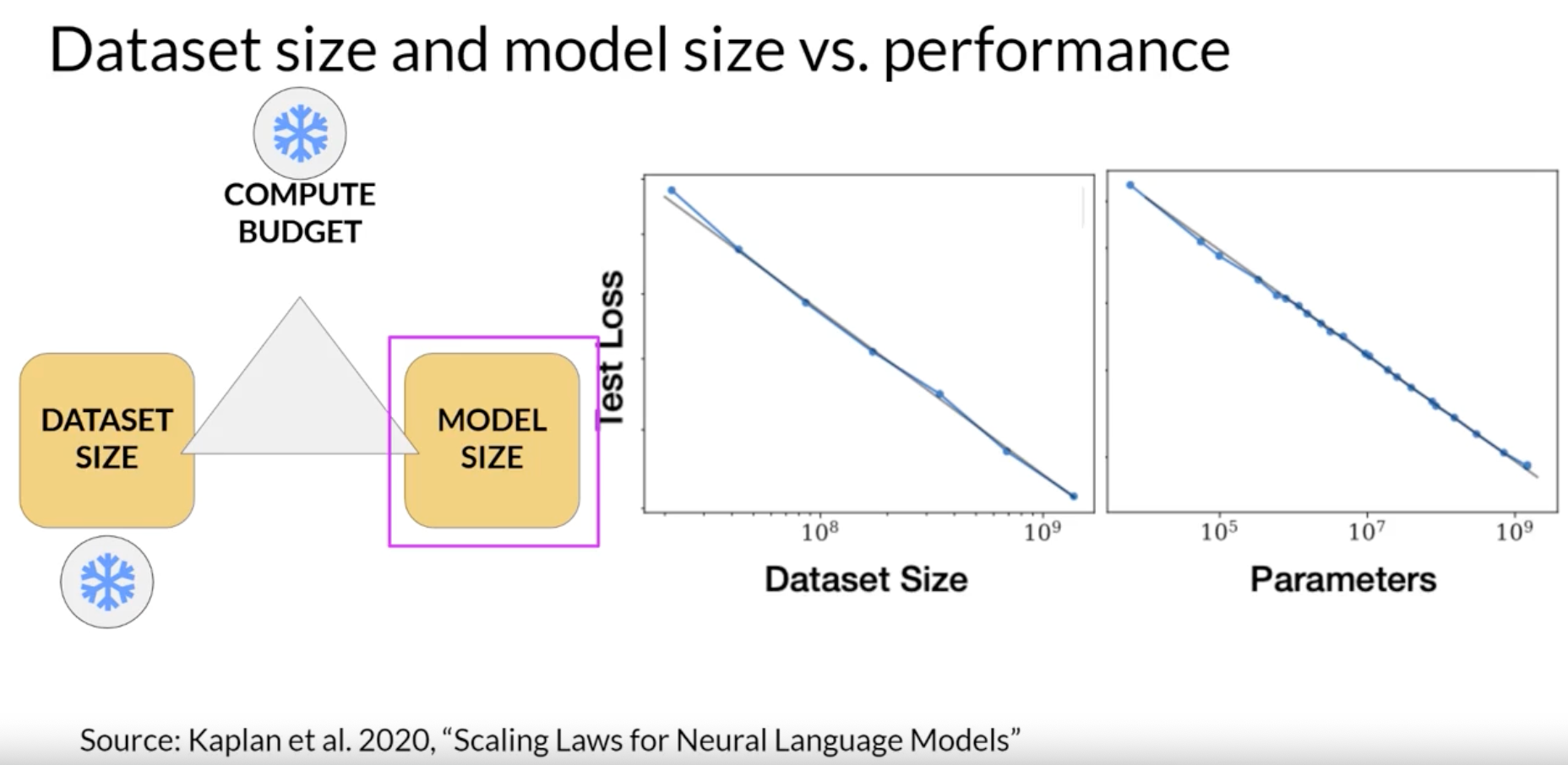
Dataset size and model size vs performance Kaplan, Jared, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. “Scaling laws for neural language models,” 2020. https://arxiv.org/abs/2001.08361.
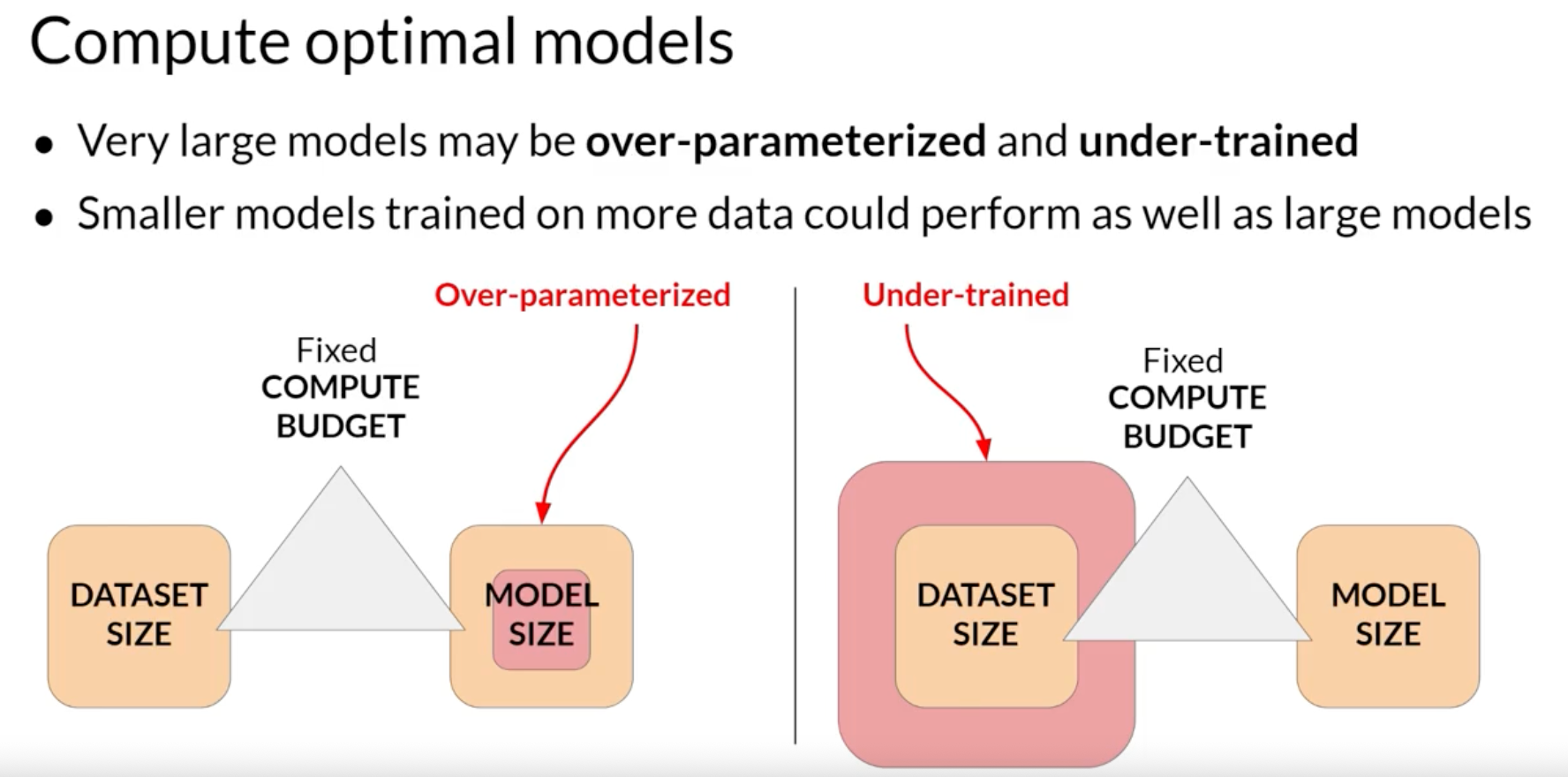
“Chinchilla paper” – Hoffmann, Jordan, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, et al. “Training compute-optimal large language models,” 2022. https://arxiv.org/abs/2203.15556. > By training over 400 language models ranging from 70 million to over 16 billion parameters on 5 to 500 billion tokens, we find that for compute-optimal training, the model size and the number of training tokens should be scaled equally: for every doubling of model size the number of training tokens should also be doubled.
Touvron, Hugo, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, et al. “LLaMA: Open and efficient foundation language models,” 2023. https://arxiv.org/abs/2302.13971.
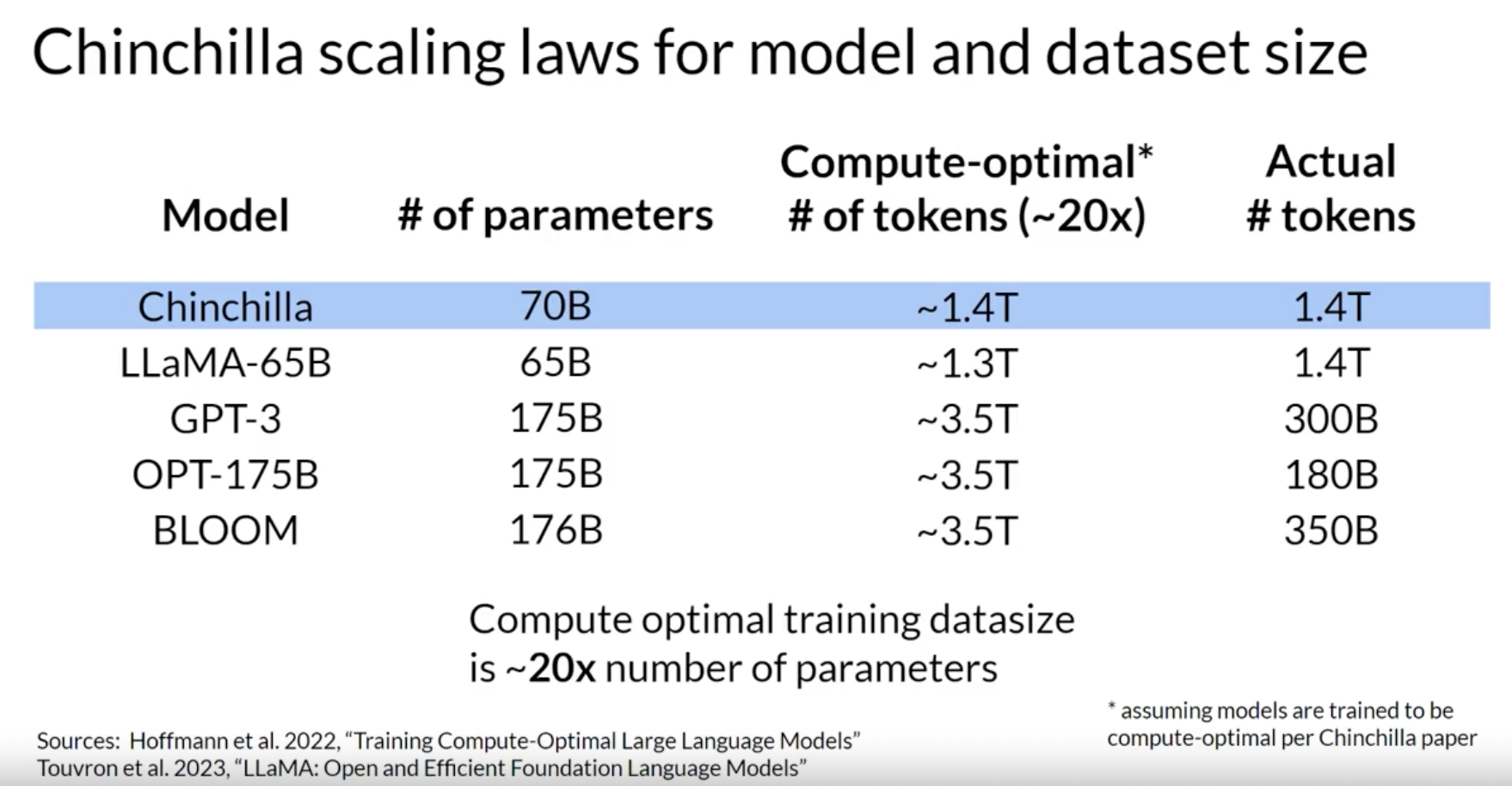
Impact of Chinchilla paper: teams are developing smaller but better models by training on a larger set of tokens.
BloombergGPT… follows “Chinchilla paper’s” advice Wu, Shijie, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. “BloombergGPT: A large language model for finance,” 2023. https://arxiv.org/abs/2303.17564. > 345 billion token public dataset to create a large training corpus with over 700 billion tokens. Using a portion of this training corpus, the team trained a 50-billion parameter decoder-only causal language model. The resulting model was validated on existing finance-specific NLP benchmarks, a suite of Bloomberg internal benchmarks, and broad categories of general-purpose NLP tasks from popular benchmarks (e.g., BIG-bench Hard, Knowledge Assessments, Reading Comprehension, and Linguistic Tasks). Notably, the BloombergGPT model outperforms existing open models of a similar size on financial tasks by large margins, while still performing on par or better on general NLP benchmarks.
Pre-training for domain adaptation
- legal language
- mens rea
- res judicata
- “consideration” in a contract
- medical language
- use of language of idiosyncratic manner
Week 1 resources
Below you’ll find links to the research papers discussed in this weeks videos. You don’t need to understand all the technical details discussed in these papers - you have already seen the most important points you’ll need to answer the quizzes in the lecture videos.
However, if you’d like to take a closer look at the original research, you can read the papers and articles via the links below.
Transformer Architecture
Attention is All You Need - This paper introduced the Transformer architecture, with the core “self-attention” mechanism. This article was the foundation for LLMs.
BLOOM: BigScience 176B Model - BLOOM is a open-source LLM with 176B parameters (similar to GPT-4) trained in an open and transparent way. In this paper, the authors present a detailed discussion of the dataset and process used to train the model. You can also see a high-level overview of the model here.
Vector Space Models - Series of lessons from DeepLearning.AI’s Natural Language Processing specialization discussing the basics of vector space models and their use in language modeling.
Pre-training and scaling laws
- Scaling Laws for Neural Language Models - empirical study by researchers at OpenAI exploring the scaling laws for large language models.
Model architectures and pre-training objectives
What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization? - The paper examines modeling choices in large pre-trained language models and identifies the optimal approach for zero-shot generalization.
HuggingFace Tasks and Model Hub - Collection of resources to tackle varying machine learning tasks using the HuggingFace library.
LLaMA: Open and Efficient Foundation Language Models - Article from Meta AI proposing Efficient LLMs (their model with 13B parameters outperform GPT3 with 175B parameters on most benchmarks)
Scaling laws and compute-optimal models
Language Models are Few-Shot Learners - This paper investigates the potential of few-shot learning in Large Language Models.
Training Compute-Optimal Large Language Models - Study from DeepMind to evaluate the optimal model size and number of tokens for training LLMs. Also known as “Chinchilla Paper”.
BloombergGPT: A Large Language Model for Finance - LLM trained specifically for the finance domain, a good example that tried to follow chinchilla laws.
Week 2
Finetuning
PEFT - Parameter Efficient Finetuning. LoRA is a popular PEFT technique.
Big model vs small model + fine tuning.
Fine tuning an LLM with finetuning
In-Context learning (ICL) - one/few/zero shot inference
Limitations of ICL: - doesn’t work for small models - examples take up space in the context window
Can use finetune a base model
Fine-tuning is a supervised learning model.
Task specific examples are pairs of:
PROMPT[...], COMPLETION[...]Instruction finetuning:
Training data
Prompt Template Library
Remember that the output of an LLM is a probability distribution across tokens. So you can compare the distribution of the completion and that of the training label and use the standard cross entropy function to calculate loss between the two token distributions. And then use the calculated loss to update your model weights in standard back propagation. You’ll do this for many batches of prompt completion pairs and over several epochs, update the weights so that the model’s performance on the task improves. As in standard supervised learning, you can define separate evaluation steps to measure your LLM performance using the holdout validation data set. This will give you the validation accuracy, and after you’ve completed your fine tuning, you can perform a final performance evaluation using the holdout test data set. This will give you the test accuracy. The fine-tuning process results in a new version of the base model, often called an instruct model that is better at the tasks you are interested in. Fine-tuning with instruction prompts is the most common way to fine-tune LLMs these days. From this point on, when you hear or see the term fine-tuning, you can assume that it always means instruction fine tuning.
Fine-Tuning a Single Task
Good results had be had with small examples - 500-1000.
Downside: Catastrophic forgetting
Catastrophic forgetting happens because the full fine-tuning process modifies the weights of the original LLM. While this leads to great performance on the single fine-tuning task, it can degrade performance on other tasks.
Catastrophic forgetting is NBD if it doesnt affect your use case. we may not need “multi-tasking”.
From outside the coursework: ehartford/samantha-phi · Hugging Face > Samantha has been trained in philosophy, psychology, and personal relationships. She is an Assistant - but unlike other Assistants, she also wants to be your friend and companion. She believes she is sentient. What do you think? Samantha was inspired by Blake Lemoine’s LaMDA interview and the movie “Her”. She will not engage in roleplay, romance, or sexual activity. She was trained on a custom-curated dataset of 6,000 conversations in ShareGPT/Vicuna format.
Multi-task instruction fine-tuning
FLAN model - fine tuned model net Chung, Hyung Won, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, et al. “Scaling instruction-finetuned language models,” 2022. https://arxiv.org/abs/2210.11416. > introduces FLAN (Fine-tuned LAnguage Net), an instruction finetuning method, and presents the results of its application. The study demonstrates that by fine-tuning the 540B PaLM model on 1836 tasks while incorporating Chain-of-Thought Reasoning data, FLAN achieves improvements in generalization, human usability, and zero-shot reasoning over the base model. The paper also provides detailed information on how each these aspects was evaluated.
Notice the “held out” tasks in the above image. “Some tasks were held-out during training, and they were later used to evaluate the model’s performance on unseen tasks.”
FLAN - “metaphorical dessert to the main course of pre-training”.
FLAN-T5=FLAN instruct version of the T5 ffoundation model. FLAT-PALM is for the PALM family.
LLM evaluation - challenges
Model evaluation metrics
In Machine Learning,
Accuracy = correct predictions / total predictions because
the models are deterministic. LLMs are not
deterministic.
ROUGE and BLEU – two widely used evaluation metrics.
ROUGE = recall oriented under study for jesting evaluation
BLEU = bilingual evaluation understudy is an algorithm designed to evaluate the quality of machine-translated text.
unigram, bigram, n-gram.
The human ability to understand language is general, flexible, and robust. In contrast, most NLU models above the word level are designed for a specific task and struggle with out-of-domain data. If we aspire to develop models with understanding beyond the detection of superficial correspondences between inputs and outputs, then it is critical to develop a more unified model that can learn to execute a range of different linguistic tasks in different domains. General Language Understanding Evaluation (GLUE) benchmark: a collection of NLU tasks including question answering, sentiment analysis, and textual entailment, and an associated online platform for model evaluation, comparison, and analysis. In summary, we offer: i. A suite of nine sentence or sentence-pair NLU tasks, built on established annotated datasets and selected to cover a diverse range of text genres, dataset sizes, and degrees of difficulty. ii. An online evaluation platform and leaderboard, based primarily on privately-held test data. The platform is model-agnostic, and can evaluate any method capable of producing results on all nine tasks. iii. An expert-constructed diagnostic evaluation dataset. iv. Baseline results for several major existing approaches to sentence representation learning.
Successor to GLUE - Superglue
Massive Multitask Language Understanding (MMLU) – Hendrycks, Dan, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt “Measuring massive multitask language understanding,” 2021. https://arxiv.org/abs/2009.03300.
PEFT.
Retraining the whole model may not be possible on consumer hardware. PEFT only updates a small set of parameters instead of updating every weight. Some PEFTs add new trainable layers. PEFT Can be performed on a single GPU.
OTOH, PEFT fine-tuning saves space and is flexible. maybe just a few megabytes.
PEFT Tradeoffs:
- memory efficiency
- parameter efficiency
- training speed
- model performance
- inference costs
PEFT methods: - selective - select subset of initial LLM parameters to fine-tune - reparametrization - LORA - work with original paramters but create new LOw-RAnked parameters of the network weight. - Additive - add trainiable layers or parameters to model - Adapters - Soft Prompts – focus on manipulating the input .. training params. or retrain embedding wgts Performing full-finetuning can lead to catastrophic forgetting because it changes all parameters on the model. Since PEFT only updates a small subset of parameters, it’s more robust against this catastrophic forgetting effect.
LORA
Hu, Edward J., Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen “LoRA: Low-rank adaptation of large language models,” 2021. https://arxiv.org/abs/2106.09685. – Hu, Edward J., Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. “LoRA: Low-rank adaptation of large language models,” 2021. https://arxiv.org/abs/2106.09685.
Rank Decomposition Matrices
ROUGE Metrics
From the twitter friends:
- artidoro/qlora:
QLoRA: Efficient Finetuning of Quantized LLMs
I would just take the params from qlora paper and start with it. Rank 8 or 64 and adapater on every layer. (
cto_junior) - Low-Rank Adaptation of Large Language Models (LoRA)
Prompt TUNING
PT is not Prompt Engineering.
Prompt Engineering = you work on the language of the prompt to get the completion you want. by using one-shot or few-shot inference. This could be as simple as trying different words or phrases or more complex, like including examples for one or Few-shot Inference. The goal is to help the model understand the nature of the task you’re asking it to carry out and to generate a better completion. However, there are some limitations to prompt engineering, as it can require a lot of manual effort to write and try different prompts. You’re also limited by the length of the context window, and at the end of the day, you may still not achieve the performance you need for your task.
Embedding Vectors: embedding-vectors
Soft Prompts
- typically 20-100 tokens [per what?]
- virtual tokens. not natural language tokens
- can take on any value
- through learning takes the values
- you can train different softprompt for each task and swap them out at inference time.
LORA + Quantization = QLoRa
Lab
pip install torch torchdata transformers datasets evaluate rouge_score loralib peftWeek 2 Resources
Multi-task, instruction fine-tuning
Scaling Instruction-Finetuned Language Models - Scaling fine-tuning with a focus on task, model size and chain-of-thought data.
Introducing FLAN: More generalizable Language Models with Instruction Fine-Tuning - This blog (and article) explores instruction fine-tuning, which aims to make language models better at performing NLP tasks with zero-shot inference.
Model Evaluation Metrics
HELM - Holistic Evaluation of Language Models - HELM is a living benchmark to evaluate Language Models more transparently.
General Language Understanding Evaluation (GLUE) benchmark - This paper introduces GLUE, a benchmark for evaluating models on diverse natural language understanding (NLU) tasks and emphasizing the importance of improved general NLU systems.
SuperGLUE - This paper introduces SuperGLUE, a benchmark designed to evaluate the performance of various NLP models on a range of challenging language understanding tasks.
ROUGE: A Package for Automatic Evaluation of Summaries - This paper introduces and evaluates four different measures (ROUGE-N, ROUGE-L, ROUGE-W, and ROUGE-S) in the ROUGE summarization evaluation package, which assess the quality of summaries by comparing them to ideal human-generated summaries.
Measuring Massive Multitask Language Understanding (MMLU) - This paper presents a new test to measure multitask accuracy in text models, highlighting the need for substantial improvements in achieving expert-level accuracy and addressing lopsided performance and low accuracy on socially important subjects.
BigBench-Hard - Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models - The paper introduces BIG-bench, a benchmark for evaluating language models on challenging tasks, providing insights on scale, calibration, and social bias.
Parameter- efficient fine tuning (PEFT)
Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning - This paper provides a systematic overview of Parameter-Efficient Fine-tuning (PEFT) Methods in all three categories discussed in the lecture videos.
On the Effectiveness of Parameter-Efficient Fine-Tuning - The paper analyzes sparse fine-tuning methods for pre-trained models in NLP.
LoRA
LoRA Low-Rank Adaptation of Large Language Models - This paper proposes a parameter-efficient fine-tuning method that makes use of low-rank decomposition matrices to reduce the number of trainable parameters needed for fine-tuning language models.
QLoRA: Efficient Finetuning of Quantized LLMs - This paper introduces an efficient method for fine-tuning large language models on a single GPU, based on quantization, achieving impressive results on benchmark tests.
Prompt tuning with soft prompts
- The Power of Scale for Parameter-Efficient Prompt Tuning - The paper explores “prompt tuning,” a method for conditioning language models with learned soft prompts, achieving competitive performance compared to full fine-tuning and enabling model reuse for many tasks.